分布式缓存系统是用于快速存取数据的软件平台,它通过在多个服务器上存储数据副本来提高访问速度和系统可伸缩性。
分布式缓存系统是现代软件架构中不可或缺的组成部分,它通过在内存中暂存数据来减少对后端存储系统的访问延迟,提高整个系统的性能,随着互联网服务的快速发展,尤其是大数据和高并发场景的普及,分布式缓存系统的重要性愈发凸显。
基本原理

分布式缓存系统通常由多个缓存节点构成,这些节点可以分布在不同的物理机器或者不同的进程中,系统对外提供统一的接口,使得客户端可以透明地存取数据,而无需关心数据实际存储的位置,当客户端请求数据时,分布式缓存系统会检查请求的数据是否已经在缓存中,如果是,直接返回结果;如果不是,从后端数据源(如数据库)加载数据,存入缓存,并返回给客户端。
关键技术点
数据分布
在分布式缓存系统中,如何高效地将数据分布到不同节点是一个核心技术问题,常见的数据分布策略包括:
1、一致性哈希:通过哈希函数将数据键映射到环状空间上,节点负责环上某个区间的数据,这种方式能够较好地处理节点增减导致的重新分布问题。
2、分片(Sharding):根据一定的规则(如取模、范围等)将数据分散到不同的节点上。
3、复制(Replication):为了提高数据的可用性和容错性,同一份数据可以复制到多个节点上。
缓存一致性
缓存一致性指的是缓存系统与后端数据源之间数据同步的一致性,保持缓存一致性通常有以下几种策略:
1、写穿:写入操作同时更新缓存和后端数据源。
2、写回:写入操作只更新缓存,当缓存数据被替换出去时再更新后端数据源。

3、写旁路:写入操作只更新后端数据源,缓存中的数据在一定时间后失效或通过订阅消息来更新。
故障转移
分布式缓存系统必须具备良好的故障转移机制以应对节点宕机等问题,这通常涉及到心跳检测、备用节点切换等机制。
扩展性与可维护性
分布式缓存系统需要能动态地添加或移除节点以应对负载变化,系统的维护操作如升级、备份等应尽量简便,不影响正常服务。
常见分布式缓存系统
市场上有多种成熟的分布式缓存解决方案,
1、Redis Cluster:提供了自动分片、复制和故障转移功能的Redis集群模式。
2、Memcached:一个高性能的分布式内存对象缓存系统,主要通过增加更多的节点来扩展缓存能力。
3、Apache Ignite:集成了内存计算网格和事务处理功能的分布式缓存系统。
4、Hazelcast:全内存数据网格解决方案,支持丰富的分布式模式。

相关问题与解答
Q1: 分布式缓存系统如何处理缓存穿透问题?
A1: 缓存穿透是指查询一个不存在的数据,由于缓存中也没有,导致每次都会去后端数据源查询,可以通过布隆过滤器(Bloom Filter)预先判断数据是否存在,避免不必要的后端查询。
Q2: 在分布式缓存系统中,如何确保数据的高可用性?
A2: 高可用性可以通过数据复制(主从复制或多副本)来实现,一旦主节点不可用,从节点或其它副本可以接管服务。
Q3: 分布式缓存系统怎样平衡性能和一致性?
A3: 这是典型的CAP理论中的权衡,根据应用场景的不同,可以选择强一致性模型(如写穿策略)或者弱一致性模型(如写回策略),在性能和一致性间找到平衡点。
Q4: 分布式缓存系统的数据持久化是如何实现的?
A4: 虽然缓存通常强调内存中的快速读写,但为了防止数据丢失,很多分布式缓存系统也提供数据持久化功能,可以将内存中的数据定期快照到磁盘上,或者记录日志以便系统重启时恢复状态。
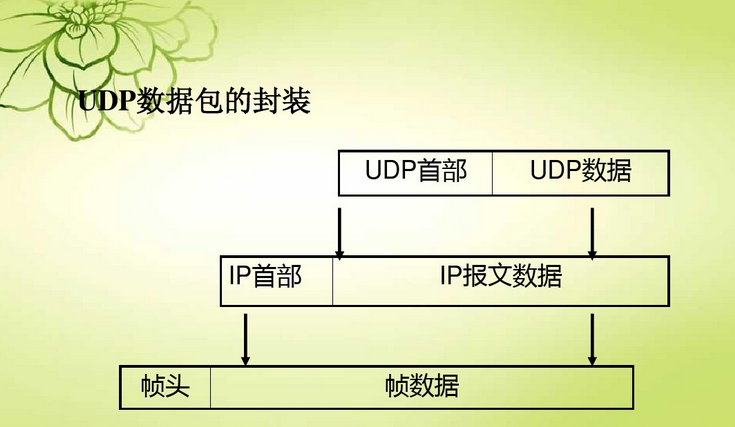






{kind=link}
{kind=link}
{kind=link}