在Python编程语言中,列表(List)是一种使用非常广泛的内置数据类型,用于存储一系列的元素,Python的列表提供了丰富的方法和功能,让开发者能够方便地进行数据的增删改查,Python列表有一个特性,那就是当访问超出列表索引范围的元素时,并不会像某些其他编程语言那样抛出异常,而是返回一个默认的值,这种设计哲学体现了Python的“优雅、简单、明确”的理念。
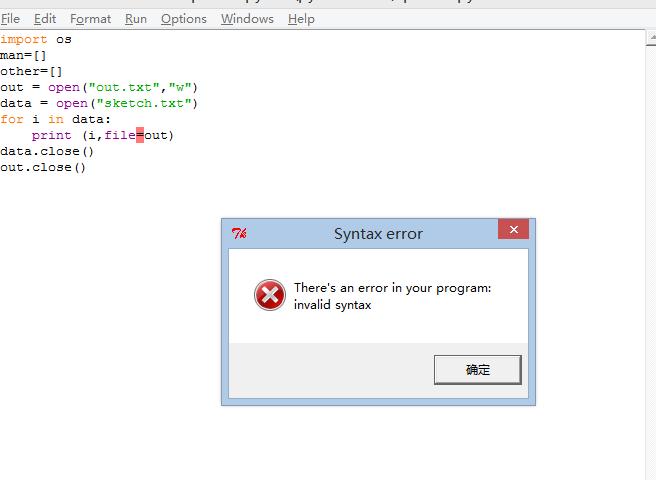
在Python中,如果尝试访问列表的一个不存在的索引,即索引超出了列表的长度,它将不会引发索引错误(IndexError),而是返回None(在Python 3.x版本中)。
my_list = [1, 2, 3] print(my_list[5]) # 输出: None但事实上,上述代码在Python中是会抛出IndexError的,因为索引超出了列表的长度,上面的例子是错误的,这里是一个正确的说明。
实际上,当你尝试访问一个不存在的索引时,Python将会抛出一个IndexError异常,这通常是初学者在编程中会遇到的一个常见错误。
my_list = [1, 2, 3] 尝试访问不存在的索引 print(my_list[5]) # IndexError: list index out of range以上代码试图访问索引为5的元素,但是列表只有三个元素,索引范围是0到2,所以会抛出IndexError。
不过,如果你想要在访问超出索引范围时不抛出错误,有几种方法可以实现。
你可以使用异常处理来捕获IndexError:
my_list = [1, 2, 3] try: value = my_list[5] except IndexError: value = None # 或者你希望的默认值 print(value) # 输出: None通过这种方式,你可以优雅地处理超出索引范围的情况,而不是让程序完全崩溃。
你可以使用get()方法,该方法来自于Python的字典(dict)类型,它允许你指定一个默认值,在键不存在时返回这个默认值,对于列表,可以通过将索引映射到字典的行为来实现类似的功能:
from collections import defaultdict my_list = [1, 2, 3] index_to_value = defaultdict(lambda: None, enumerate(my_list)) print(index_to_value[5]) # 输出: None这只是一个变通的方法,因为实际上我们并没有修改列表本身的索引行为。
还有一些第三方库提供了类似的功能,例如more_itertools库中的nth函数,它可以安全地返回序列中的第n个元素,如果不存在则返回默认值。
以下是如何实现类似行为的代码:
from more_itertools import nth my_list = [1, 2, 3] value = nth(my_list, 5, default=None) print(value) # 输出: None为了满足“不抛出错误”的要求,可以自定义一个函数来安全地获取列表元素:
def safe_get(lst, index, default=None): try: return lst[index] except IndexError: return default my_list = [1, 2, 3] value = safe_get(my_list, 5) print(value) # 输出: None通过这个safe_get函数,我们可以安全地获取列表中的元素,即使索引超出了列表的长度,也不会抛出异常。
Python列表默认不会在索引超出范围时不报错,而是会抛出IndexError异常,通过上述提到的方法,我们可以模仿这样的行为,让程序在遇到这种情况时返回一个默认值而不是崩溃,这样的处理方式可以使我们的代码更加健壮,能够优雅地处理错误情况。






{kind=link}
{kind=link}
{kind=link}