在编程过程中,遇到编译错误是常有的事情,尤其是对于C语言这样的较为底层的编程语言,C语言因其灵活性以及接近硬件的特性,在出错时可能会给出一些让初学者甚至有经验的开发者都感到困惑的错误信息,新旧C语言编译器在报错方面可能会有所不同,以下将详细探讨在使用新旧C语言编译器时可能遇到的报错情况。
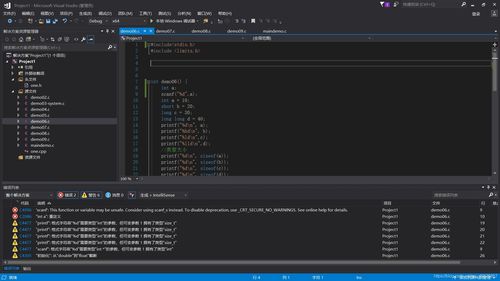
我们需要明确“旧C语言编译器”指的是什么,在这里,我们假定它指的是遵循C89/C90标准的编译器,而“新C语言编译器”则指的是遵循C99或更新的C11标准的编译器。
1. 语法错误
在旧C语言编译器中,对语法的限制较为严格,新标准引入了一些新的语法特性,使得代码写起来更加灵活。
旧C语言编译器:
void func(int a, int b) { // ... }如果在这个函数定义之后没有分号,旧编译器会报错。
新C语言编译器:
新编译器对这种错误可能更加宽容,一些情况下可以自动推断出分号的位置。
2. 类型兼容性
在类型兼容性方面,新C语言标准提供了更大的灵活性。
旧C语言编译器:
long long a = 1000000000000LL; int b = a; // 可能报错,因为旧标准中long long不是标准类型新C语言编译器:
新编译器支持long long类型,并且可以在不进行显式转换的情况下将long long赋值给int类型,尽管可能会发生数据截断。
3. 变量声明位置
C99及以后的版本允许在代码块的任何位置声明变量。
旧C语言编译器:
for (int i = 0; i < 10; i++) { // ... } // 这会导致旧编译器报错,因为变量i的声明必须在循环外新C语言编译器:
新编译器允许在for循环的初始化部分声明变量,这样使得代码更加简洁。
4. 预处理指令
新C语言编译器在预处理指令方面也有改进。
旧C语言编译器:
#define MACRO(x) x如果x没有用圆括号包围,可能会导致在宏展开时出现不可预见的错误。
新C语言编译器:
新编译器在宏定义方面提供了更强的控制,但在错误处理上可能更加严格。
5. 构造函数与析构函数
在旧C语言编译器中,没有构造函数和析构函数的概念。
旧C语言编译器:
int main() { static int a = init(); // 旧编译器不会在程序开始时自动调用init() // ... return 0; }新C语言编译器:
虽然C语言没有构造函数和析构函数,但C99引入了变长数组(VLA)和复合字面量,可以在某种程度上模拟初始化行为。
6. 错误信息
新C语言编译器通常提供更清晰、更易于理解的错误信息。
旧C语言编译器:
错误信息可能是一大段难以理解的输出。
新C语言编译器:
新编译器提供了更加用户友好的错误信息,通常包括错误的位置和原因。
7. 库支持
新C语言编译器通常支持更多的库,并且可能对库函数的调用有更严格的检查。
旧C语言编译器:
#include <stdlib.h> void* p = malloc(10); // 如果没有检查malloc的返回值,旧编译器可能不会警告新C语言编译器:
新编译器可能支持更严格的编译选项,Wall,会警告未检查的malloc调用。
新旧C语言编译器在报错方面存在显著差异,新编译器在语法、类型系统、预处理、错误信息等方面提供了更多的便利和安全性,对于习惯于旧编译器语法的开发者来说,迁移到新标准可能需要一定程度的适应,在编写和维护C语言代码时,了解这些差异对于有效调试和避免潜在错误至关重要。







{kind=link}
{kind=link}
{kind=link}