在处理Hive数据时,遇到读取数据报错是一个常见的问题,根据提供的参考信息,我们可以推测这些问题可能涉及Hive的元数据配置、HDFS数据文件的误删,以及与MySQL的连接问题,以下是对这些问题的详细解析和可能的解决方案。
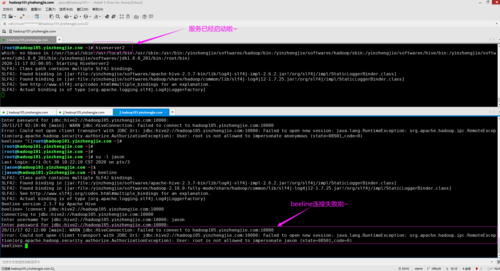
当在Hive中执行HQL查询时,如果遇到“SQL语句在增加group by之后查询无数据,没有group by则查询有数据”的问题,这通常表明查询执行计划可能存在问题,或者元数据出现了不一致,这种情况可能是由于以下原因引起的:
1、元数据不一致:删除HDFS中的Hive数据文件而没有通过Hive的DROP TABLE命令可能导致元数据和实际数据存储不一致,当执行包含group by的查询时,Hive需要依赖这些元数据来正确地执行查询。
2、数据文件损坏:删除和重新创建Hive表可能导致数据文件损坏,特别是在没有正确关闭Hive表的情况下。
针对这个问题,以下是一些建议的解决方案:
确认元数据一致性:使用Hive的DESCRIBE FORMATTED命令检查表的元数据,确保元数据与HDFS上的数据文件一致。
修复元数据:如果发现元数据不一致,可以通过Hive的ALTER TABLE命令来修复表的元数据。
使用Hive重建表:如果上述步骤无法解决问题,可以考虑删除表并从原始数据重新创建表。
检查Hive配置:确认Hive的配置文件(如hivesite.xml)中的参数设置正确,特别是与元数据存储相关的配置。
XShell连接MySQL异常(错误2002)通常表明MySQL的服务器或客户端配置存在问题,参考信息中提到的解决方案是执行MySQL的configtar.sh脚本,这个脚本可能包含了修复MySQL配置、启动服务的命令,以下是其他可能的方法:
检查MySQL服务状态:确认MySQL服务正在运行,并且监听正确的端口。
检查socket文件:确认MySQL的socket文件(如/tmp/mysql.sock)存在,并且拥有正确的权限。
使用TCP/IP连接:如果socket连接不工作,尝试使用基于TCP/IP的连接,配置正确的hostname和port。
对于Hive与Spark的结合使用,出现连接问题和SSL错误也是常见的情况,以下是对这些问题的处理建议:
配置文件同步:确保Spark的配置目录下有正确的hivesite.xml文件,并同步了Hive的所有关键配置。
权限设置:确保Hive在MySQL中拥有足够的权限来访问和修改元数据库。
SSL配置:如果遇到SSL错误,检查hivesite.xml中的JDBC URL是否包含正确的SSL配置参数。
对于Spark与Hive的读写操作报错,以下是一些额外的建议:
确认Hive支持:检查Spark的配置,确保它包含了与Hive兼容的依赖和设置。
检查Hive版本:确保Hive的版本与Spark中的Hive支持版本相匹配。
使用正确的命令:在Spark中读取和写入Hive表时,使用正确的HiveContext或SparkSession命令。
解决Hive读数据报错的问题需要多方面的考虑,包括元数据一致性、配置文件、权限设置、服务状态,以及与外部服务(如MySQL)的连接,通过上述方法,应该能够定位并解决大多数与Hive数据读取相关的问题,在处理这些问题时,耐心和细致是关键,确保每一步操作都符合预期的行为和配置标准。





{kind=link}
{kind=link}
{kind=link}